Die in dieser Arbeit vorgestellten Algorithmen haben wir in dem Programm LiLit4.1 realisiert. Es handelt sich dabei um einen Prototyp, den wir zur Implementierung der wesentlichen Algorithmen verwendet haben. Es wurde dabei weniger auf grafische Benutzeroberflächen, Fehlerbehandlung und erweiterte Funktionalität Rücksicht genommen. LiLit ist größtenteils objektorientiert in ANSI C++ geschrieben worden. Aufgrund der Größe von LiLit werden wir hier nur die grobe Struktur des Programms vorstellen.
LiLit liest zunächst die zu bearbeitenden Objekte aus einer Datei im ODL-Format (siehe unten) ein. Der hierzu notwendige Parser wurde mit bison++ erstellt. Der Parser verwendet einen mit flex++ erzeugten lexikographischen Scanner. Er wandelt die ODL-Darstellung in die interne Darstellung der Objekte durch die Klasse World um. Diese Klasse enthält eine Liste aller in der Datei beschriebenen Objekte, eine Liste der Objekte, die angezeigt werden sollen und eine Liste der zu berechnenden Integrale. Weiter enthält World noch allgemeine Informationen zum Rendern und Bearbeiten der gesamten Szene. Die Objekte werden alle durch eine von der abstrakten Klasse Object abgeleiteten Klasse dargestellt.
Im nächsten Schritt bearbeitet LiLit allgemein alle Objekte, die angezeigt bzw. integriert werden sollen. Zusätzlich müssen wir auch Objekte bearbeiten, die indirekt von diesen Objekten benutzt werden. In diesem Schritt werden die G-Spline-Kontrollnetze zusammen mit eventuell vorhandenen Funktionskontrollnetzen in Bézierkontrollnetze umgewandelt. Als Ergebnis erhalten wir zu den Objekten eine einfachere Beschreibung, die zum Integrieren und Rendern verwendet werden kann.
Sollen Oberflächenintegrale berechnet werden, werden anschließend die zugehörigen Integrationsmethoden aufgerufen. Die Ergebnisse werden so gespeichert, daß sie im folgenden Schritt einfach angezeigt werden können.
Schließlich werden alle Objekte, die angezeigt werden sollen, mit Hilfe von OpenGL und GLUT gerendert. Für die Bézierkontrollnetze der Flächen können wir die Standardfunktionen verwenden. Zur Darstellung der Funktionen auf den Flächen müssen wir die Bézierkontrollnetze zunächst entsprechend auswerten und die Normalen, Flächen, etc. durch OpenGL-Primitives rendern. Bei Isolinien werden die Linien sogar erst jetzt berechnet. Wir speichern die OpenGL-Primitives in Display-Listen, um die Szene schnell neu anzeigen zu können. Nachdem alle Primitives erzeugt wurden, kann der Benutzer im interaktiven Modus von LiLit den Beobachtungspunkt verändern.
Neben dem direkten Anzeigen der Objekte in einem X11-Fenster kann man die Szene auch in einer PostScript-Datei speichern. Wir benutzen hierzu den Feedback-Buffer von OpenGL. Die grundlegende Idee hierfür stammt aus der GLP-Bibliothek von Michael Sweet. OpenGL transformiert zunächst die drei-dimensionalen Grafikobjekte in zwei-dimensionale Objekte. Erst im nächsten Schritt werden diese Objekte für die Grafikausgabe gerastert. Wir können OpenGL nun dazu veranlassen, nur die zwei-dimensionalen Primitives aus dem ersten Schritt zu erzeugen und diese im Feedback-Buffer abzulegen. Der Buffer enthält nur Punkte, Linien und Polygone. Er kann auch noch Bitmaps enthalten, die wir aber für LiLit nicht verwenden und damit ignorieren können. Die Punkte und Linien lassen sich direkt in PostScript übertragen. Die Polygone wandeln wir in Dreiecke um und zeichnen diese Dreiecke mit PostScript. Neben den zwei-dimensionalen Koordinaten hat jeder Punkt im Feedback-Buffer auch noch eine Z-Buffer-Koordinate. Mit Hilfe dieser Koordinaten können wir die Punkte, Linien und Dreiecke sortieren und die am weitesten hinten liegenden Primitives zuerst zeichnen. Dies ergibt einen einfachen Überdeckungsalgorithmus, der bei kleinen Primitives durchaus ausreicht. Die so erzeugte PostScript-Datei kann dann frei skaliert werden. Bei sehr vielen Primitives wird sie aber sehr schnell sehr groß. In diesen Fällen hilft es aber, die Auflösung der drei-dimensionalen Objekte zu verringern.
LiLit wurde für UNIX-ähnliche Systeme entwickelt. Die Entwicklungsplattform war ein erweitertes Debian/GNU 2.0 Linux System4.2. Linux ist nicht nur eine sehr stabile Plattform, sondern eignet sich auch ideal als Entwicklungsumgebung wegen der OpenSource4.3 Philosophie und dem Free Software Konzept von GNU4.4. Aus diesem Grund wird auch LiLit selbst als freie Software unter der GNU General Public License vertrieben.
Die wesentlichen Programmteile wurden in ANSI C++ geschrieben. Um die Kompatibilität zwischen den UNIX-Varianten zu sichern, wurden manche Funktionen, die nicht in jeder libc Implementation gleich sind, in C geschrieben. Weiter wurde GNU autoconf4.5 2.12 zur Konfiguration des Quellcodes für die verschiedenen Systeme verwendet. Damit ist LiLit einfach auf viele andere UNIX-Varianten zu portieren.
Das Programm wurde mit der erweiterten GNU C Compiler Suite, egcs4.6Version 1.0.3 und 1.1 übersetzt. Weiter wurde die C++ Version des GNU Fast Lexical Analyzer Generators flex++ Version 2.5.4 und bison++ Version 1.21-7, welches von dem GNU Project Parser Generator bison4.7abgeleitet wurde, verwendet. Neben den Standard UNIX und X11R6 Bibliotheken wird auch noch LaPack4.8mit BLAS benötigt. Als Grafikbibliothek muß eine zum OpenGL Standard kompatible Bibliothek mit GLUT vorhanden sein. Ausführlich wurde dies aber nur für die freie OpenGL Implementierung Mesa4.9 ab Version 3 getestet.
Der Quellcode von LiLit wurde mit dem Dokumentationssystem DOC++4.10kommentiert. Diese Dokumentation ist im Anhang A zu finden.
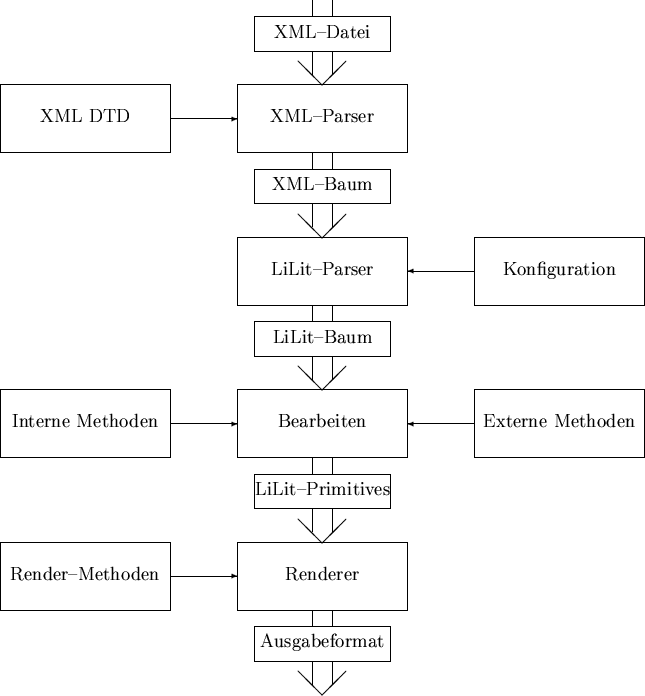
Wie schon erwähnt, handelt es sich bei LiLit nur um einen Prototyp, der allerdings den in dieser Arbeit benötigten Funktionsumfang schon vollständig enthält. Abbildung 4.1 zeigt eine verbesserte Struktur für LiLit. Die ODL-Datei wurde hier durch ein über XML4.11 (eXtensible Markup Language) definiertes Format ersetzt. Das Format selbst wird über eine DTD (Document Type Definition) festgelegt und kann somit einfach erweitert und modularisiert werden. Der XML-Parser wandelt die Eingabedatei in einen XML-Baum um. Aus diesem Baum könnte über eine externe Beschreibung der vorhandenen Objekte und Methoden eine interne Repräsentation der Eingabedatei erzeugt werden. Diese Daten können dann im folgenden Schritt zu LiLit-Primitives umgewandelt werden. Hierzu können sowohl interne als auch externe, dynamisch ladbare, Methoden verwendet werden. Dabei sollten die internen Methoden nur einen minimalen Funktionsumfang zur Verfügung stellen. Alle komplexeren Objekte könnten durch die externen Methoden bearbeitet werden. Welche Methoden hier zur Verfügung stehen, ließe sich durch eine Konfigurationsdatei angeben. Neben dynamisch ladbaren Methoden könnte man zusätzlich eine Skriptsprache entwickeln, über die man schon vorhandene Methoden auf komplexere Objekte anwenden kann. Die so erzeugten LiLit-Primitives ließen sich schließlich über Render-Methoden darstellen. Dabei kann man natürlich verschiedene Ausgabeformate unterstützen.
Die momentane Version von LiLit verwendet noch ODL-Dateien und nicht XML für die Eingabe und alle Methoden zum Rendern und Bearbeiten sind intern implementiert ohne externe Konfigurationsdateien.