C. Jenkins, M. Chandler, F. C. Langbein, S. M. Shermer. Benchmarking GABA Quantification: A Ground Truth Data Set and Comparative Analysis of TARQUIN, LCModel, jMRUI and Gannet. Submitted, 2021. [arxiv:1909.02163] [PDF]
 Many tools exist for the quantification of GABA-edited magnetic resonance spectroscopy (MRS) data. Despite a recent consensus effort by the MRS community, literature comparing them is sparse but indicates a methodological bias. While invivo data sets can ascertain the level of agreement between tools, ground-truth is required to establish accuracy, and investigate the sources of discrepancy.
Many tools exist for the quantification of GABA-edited magnetic resonance spectroscopy (MRS) data. Despite a recent consensus effort by the MRS community, literature comparing them is sparse but indicates a methodological bias. While invivo data sets can ascertain the level of agreement between tools, ground-truth is required to establish accuracy, and investigate the sources of discrepancy.
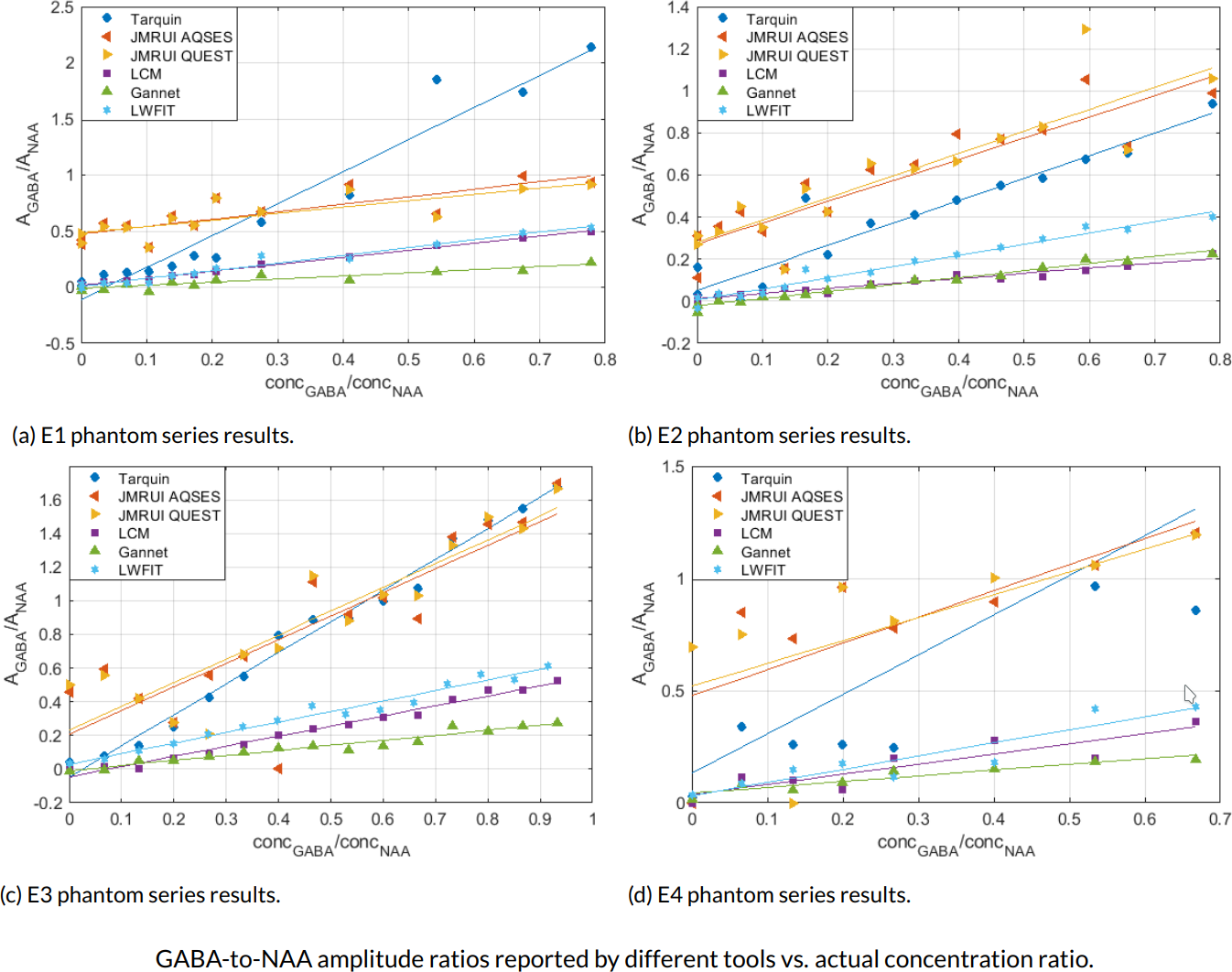
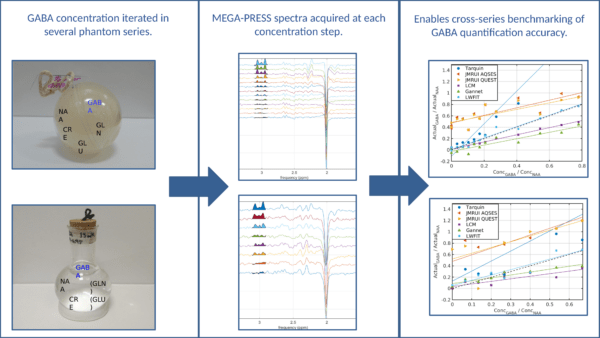
We present a novel approach to benchmarking GABA quantification tools, using several series of phantom experiments with iterated GABA concentration. Each series presents a different set of background metabolites and environmental conditions allowing comparison of not only individual estimates, but the ability of tools to characterise changes in GABA across a range of potential confounds. The methodology of the phantom experiments is presented, as well as characterisation of the data. We also perform an initial comparative analysis of several common MRS quantification tools (LCModel, TARQUIN, jMRUI, Gannet) and in-house code (LWFIT), to illustrate utility of the dataset and the potential bias introduced by different quantification methods. The GABA-to-NAA ratios reported by each tool are compared to the ground-truth, and estimation accuracy is assessed by linear regression of this relationship.
While the linearity of GABA-to-NAA gradients is generally captured by all of the tools, a large variation in the slope, offset and environmental stability of the gradient is observed. The primary driver of differences in linear combination modelling is the choice of basis function. However, tools employing a common basis and pre-processing still produce differences on the order of $4\%$. Less-strictly parametrised fitting approaches appear to improve the robustness of quantification, but accurate modelling of edit efficiency calculations is still necessary to avoid systematic offsets. In general, the level of variation suggests that comparisons across quantification methods should be performed tentatively, and the sharing of basis sets and optimisation options is an important step towards greater reproducibility of invivo MRS studies.
![]() This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.